
今回は深層強化学習の一つであるDeep Q Networkについて紹介します。
実装にはTensorFlowを用いました。
Deep Q Networkとは
Deep Q Network(DQN)は強化学習の一手法です。
DQNは強化学習のQ学習をベースとした手法でAtariの様々なゲームで
人間を凌駕したアルゴリズムです。
DQNでは、Q学習のQテーブルをニューラルネットワークで関数近似しています。

単純なQテーブルでは、行動と状態数が膨大な時に、
Qテーブルの必要なメモリ空間が大きくなりすぎてしまう問題がありました。
そこで、Qテーブルをニューラルネットワークで関数近似することにより、
メモリ空間の爆発問題を防いでいます。
さらにDQNでは、Experience Replay、Target Network、Reward Clipping等の工夫を加えることにより学習性能を向上させています。
以下で詳しく説明していきます。
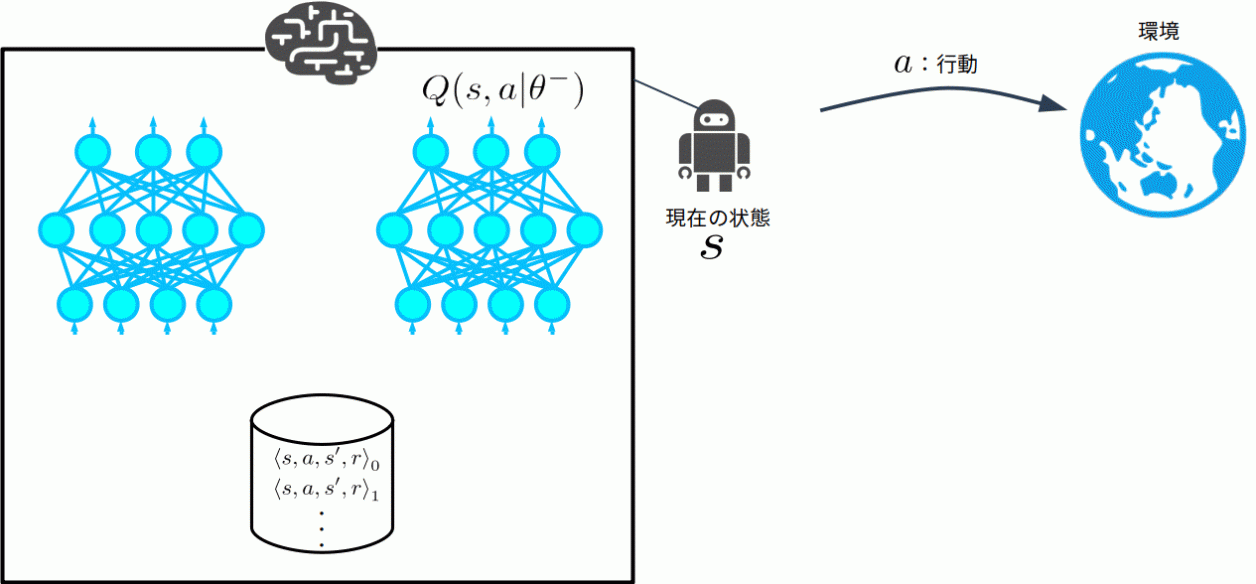
Deep Q Networkの構成
Deep Q Networkは以下の図のようになります。

エージェントはTarget Network\(Q(s’, a|\theta^{-})\)とQ Network\(Q(s’, a|\theta)\)というニューラルネットワークを保持しています。
この2つのネットワークの構造は同一です。パラメータは異なります。
このネットワークの入力は状態、出力はQ値になります。
得られた経験\(\langle s, a, s’, r \rangle \)を保存するためのExperience Bufferを保持しています。
Deep Q Networkの学習の流れ
DQNの学習の流れは以下のようになります。
- 現在の状態\(s\)をTarget Network\(Q(s’, a|\theta^{-})\)に入力
- Target Networkから出力されたQ値を元に行動選択
- 行動したことによって変化した状態 \(s’\) と報酬\(r\)の観測
- 経験\(e=\langle s, a, s’, r \rangle \)をExperience Bufferに保存
- Experience Bufferから任意の経験を取り出し、Q Networkをミニバッチ学習(Experience Replay)
- Target Networkの更新
簡単な図を使って各手順を説明していきます。
1. 現在の状態\(s\)をTarget Network\(Q(s’, a|\theta^{-})\)に入力
まず、現在の状態\(s\)をTarget Network\(Q(s’, a|\theta^{-})\)に入力し、Q値\(Q(s’, a|\theta^{-})\)を得ます。

2. Target Networkから出力されたQ値を元に行動選択
Q値\(Q(s’, a|\theta^{-})\)を元にε-greedy選択などで行動\(a\)を選択します。
3. 行動したことによって変化した状態 \(s’\) と報酬\(r\)の観測
環境から遷移先状態\(s’\) 及び報酬\(r\)を観測します。

4. 経験\(e=\langle s, a, s’, r \rangle \)をExperience Bufferに保存
「現在の状態\(s\)で行動\(a\)によって状態\(s’\)に遷移し、報酬\(r\)を得た」という経験\(e=\langle s, a, s’, r \rangle \)をExperience Bufferに保存(記憶)します。
ここで、報酬値\(r\)を-1〜1の範囲にクリップします。
単純な方法としては1以上であれば1に。
-1以下であれば-1に報酬をクリップします。
これは外れ値等に過剰に反応しすぎないために行います。
この処理をReward Clippingと言います。

5. Experience Bufferから任意の経験を取り出し、Q Networkをミニバッチ学習(Experience Replay)
定期的にQ Networkの学習を行います。
Experience Bufferからバッチサイズ分経験をサンプリング(\(B={e_0, e_1, …, e_{|B|} } \)) し、
以下のTD誤差\(\mathcal{L}(\theta)\)を最小化するようにQ Networkのパラメータ\(\theta\)を更新します。
\begin{eqnarray}
\mathcal{L}(\theta) = \frac{1}{|B|}\sum_{e \in B} (r + \gamma \max_a Q(s’, a|\theta^{-}) – Q(s, a|\theta))^2
\end{eqnarray}
$$
この処理をExperience Replayと言います。

6. Target Networkの更新
任意のインターバルで、Q NetworkのパラメータをTarget Networkに反映していきます。
これは、Q Learningの過大評価という課題を緩和するために重要なります。
Q Networkのパラメータの反映方法には大きくわけて2つあって、
1つはHard Update、もう1つはSoft Update になります。
Hard Updateでは、定期的にQ NetworkのパラメータをTarget Networkにコピーします。
Soft Update では、Q Networkを更新する度に少しずつQ Networkのパラメータを反映させていきます。

実装と実験
TensorFlow(+Keras)を使って実装してみました。
cartpole問題を用いて、実験します。
Cartpole問題とは
CartPoleは、棒が設置してある台車があり、
台車を棒が倒れないように
うまくコントロールする問題になります。

出典:Leaderboard · openai/gym Wiki · GitHub
制御値、観測、報酬等について
制御値(行動)
制御値は、台を左に押す(0)か 右に押す(1)の二択になります。
| 操作 | |
|---|---|
| 0 | 左に押す |
| 1 | 右に押す |
観測
観測値は、台車の位置、台車の速度、棒の角度、棒の先端の速度の4つになります。
| 観測情報 | 最小値 | 最大値 |
|---|---|---|
| 台車の位置 | -2.4 | 2.4 |
| 台車の速度 | -inf | inf |
| 棒の角度 | -41.8° | 41.8° |
| 棒の先端の速度 | -inf | inf |
報酬
報酬としては1を与え続けます。
エピソードの終了判定
以下のどれかの条件を満たした場合に、
エピソードが終了したと判定されます。
- ポールのアングルが±12°以内
- 台車の位置が±2.4以内
- エピソードの長さが200以上
ソースコードと解説
ソースコード
一部解説(注意すべき点)
Q Networkを学習する時に注意する必要があります。
経験\(\langle s, a_0, r, s’ \rangle\)が与えられた時に\(Q(s, a_0)\)だけを学習させるために 少し工夫を加えます。 余計な学習をしないように、Q Networkの出力とtarget\(r+\gamma \max_a Q(s’,a|\theta^{-})\)にマスク処理を行います。
図を用いて説明します。
単純に学習しようとすると、以下の図のようにすべての出力層を考慮してしまいます。 
しかし、今回考慮したいのは行動\(a_0\)に対する評価のみです。
なので、余計な学習をしないように、\(a_1, a_2\)を無視する必要があります。
つまり、出力\(Q(s, a_1), Q(s, a_2)\)と\(a_1, a_2\)に対応したTD Targetを0にし、学習しないようにします。

ソースコード上では、120行〜122行の部分になります。
one hot encodingを用いて対処しています。
実験結果

横軸はepisode、縦軸はpoleが立っていられたステップ数を表します。
poleが立っていられる最大ステップは200ステップです。
エピソードが進むごとにpoleを200ステップ立たせられていることがわかります。
